
Wstęp
Technologie wykorzystywane w machine learning pozwalają gromadzić, analizować i przetwarzać dane. W przypadku cyberbezpieczeństwa pomagają lepiej analizować występujące ataki i dostosowywać odpowiednie reakcje obronne. Takie podejście umożliwia utworzenie zautomatyzowanego systemu cyberbezpieczeństwa uczącego się w czasie rzeczywistym. Dzięki temu cyber-ataki są coraz łatwiejsze do przewidzenia i często wykrywane zanim jeszcze nastąpią.
Dzisiejsi cyberprzestępcy również uzbrojeni są w sztuczną inteligencję i algorytmy wykorzystujące machine learning. Podkreśla to fakt, że należy stale inwestować w systemy i badania mogące przeciwdziałać wyszukanym atakom. Używanie tych samych narzędzi po obu stronach, pozwala zaawansowanym systemom bezpieczeństwa na szybkie uczenie się wzorców i wykrywaniu nieprawidłowości, w sposób o jakim tradycyjne metody, np. sygnatury, mogłyby tylko pomarzyć. Machine learning uzyskuje dużą przewagę dzięki temu, że nie potrzebuje wcześniejszej wiedzy na temat zagrożenia, aby mu zapobiec. Wkraczamy więc w nową erę, w której departamenty bezpieczeństwa w organizacjach, zaczynają analizować ataki zanim jeszcze nastąpią.
Po co bezpieczeństwu Machine Learning?
Głównym zadaniem machine learning w cybersecurity jest wykrywanie anomalii, czyli zachowań użytkowników i urządzeń, które są odmienne od tego co występuje zazwyczaj. Sporym wyzwaniem jest odróżnienie zachowania nietypowego od normalnego. Każde użycie laptopa poza miejscem pracy lub pobranie aplikacji z sieci może być traktowane jako anomalia. Dlatego, często systemy bazujące na machine learning są niesłusznie oceniane jako producenci dużej ilości alarmów ,,false positive”. Należy mieć na uwadze, że systemy te wykrywają anomalie w środowisku, a nie konkretne malware’y czy podatności. Działanie ich jest szersze niż oprogramowania opartego na sygnaturach.
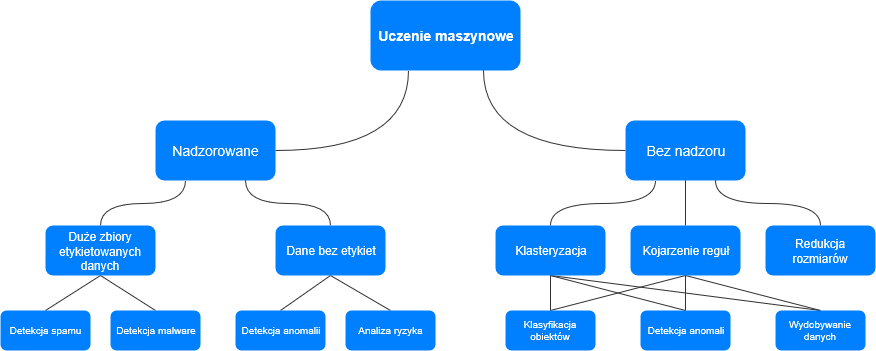
Jak już wiadomo z tekstu Uczenie Maszynowe – słownik pojęćy uczenie maszynowe dzielimy na dwie kategorie pozyskiwania wiedzy o analizowanych danych – nadzorowane oraz bez nadzoru. Uczenie nadzorowane sprawdzi się wszędzie tam, gdzie dane dostarczane są dobrze oznaczone i bogate w parametry. Z kolei metody używane w uczeniu bez nadzoru, takie jak klasteryzacja, kojarzenie reguł oraz redukcja rozmiarów służą do grupowania danych i do ich lepszego zrozumienia w dalszej analizie.
Nie da się ukryć, że najlepsze efekty machine learning osiąga przy wykrywaniu złośliwego oprogramowania oraz przy klasyfikacji spamu. Pierwsze z nich polega na określeniu czy dany plik jest szkodliwy czy też możemy go uruchomić bez żadnych ,,efektów ubocznych”. Dzisiejsze postępy w tej dziedzinie pozwoliły ograniczyć zarówno ilość alarmów ,,false negative” jak i ,,false positive” do minimum. Jest to możliwe dzięki istniejącej ogromnej bazie znanego, złośliwego oprogramowania oznaczonego etykietami. Jest to idealny wręcz zestaw danych uczących dla algorytmów machine learning pozwalający wytrenować zachowania sztucznej inteligencji w systemach bezpieczeństwa.
Analogicznie jest przy detekcji wiadomości zwierających spam. Istnieje wiele danych szkoleniowych, na których algorytmy ML mogą opierać swoją wiedzę w tym zakresie.
Wyzwaniem dla systemów machine learning wciąż jest analiza ataków sieciowych. Tutaj danych uczących jest zdecydowanie mniej, a różnorodność zagrożeń rośnie z dnia na dzień. Metody uczenia bez nadzoru pomagają grupować rekordy danych, jednak problemem jest klasyfikacja ich ze względu na ,,normalne” i ,,anormalne”. Całkiem dobrze sprawdza się tutaj klasteryzacja. Należy wtedy dobrać tylko odpowiednie parametry dla analizowanego środowiska, takie jak funkcje odległościowe, liczbę iteracji algorytmu itp.
Konkrety
Jeden z najbardziej popularnych algorytmów uczenia maszynowego nadzorowanego to „random forest”, który swoje działanie opiera na prostym drzewie decyzyjnym. Dzięki niemu możliwa jest analiza i wykrycie na przykład ataku command-and-control poprzez ruch HTTP. Random forest analizuje w tym przypadku cechy w nagłówkach HTTP w celu zidendyfikowania wzorców zachowań typu command-and-control, które nie występują w znanym, nieszkodliwym ruchu sieciowym. Mając duży zasób danych, algorytm może wykrywać ataki bez używania sygnatur, co eliminuje problem nadążania za atakującymi, którzy ciągle zmieniają domeny i adresy IP swoich urządzeń.
Kolejnym przykładem wykorzystywanym w praktyce jest klasteryzacja i jej zautomatyzowany algorytm zwany algorytmem centroidów. Po ustawieniu odpowiednich parametrów jest w stanie wychwycić anomalie na podstawie odchyleń danych od grupy. Może być użwany na przykład do identyfikacji kradzieży poświadczeń z zainfekowanego urządzenia. Obejmuje to techniki hakerskie Pass-the-hash i Golden Ticket, polegające na kradzieży i wykorzystywaniu tokenów z zaufanych urządzeń lub tworzeniu fałszywych. Aby zidentyfikować te incydenty monitorowany jest ruch Kerberos w celu ustanowienia norm dla różnych zachowań dla każdego hosta w sieci. Obejmuje to logowania użytkowników, a także monitorowanie usług, o które użytkownicy zwykle proszą. Zazwyczaj, po kompromitacji poświadczeń użytkownika, konto zaczyna logować się nowych hostach oraz żądać nowych usług. Dzięki klasteryzacji możliwe jest ujawnienie takiego ataku w czasie rzeczywistym i wykrycie momentu kiedy poświadczenia zostały skradzione. Dalsza analiza może ujawnić w jaki sposób konto zostało skompromitowane oraz czy atakujący uzyskał dostęp do uprzywilejowanych obszarów w sieci.
Jedną z bardziej interesujących podkategorii machine learningu jest ,,deep learning”. Uczenie głębokie polega na stosowaniu sieci neuronowych do analizowania złożonych problemów. Opiera swoje działanie na połączonych ze sobą setkach neuronów, z których każdy jest niezależnym procesem lub wątkiem z własną pamięcią lokalną. Pozwala to na obliczenia wykonywane równolegle i dzielenie się wynikiem z siąsiadami w czasie rzeczywistym. Deep learning używany jest dziś przede wszystkim w rozpoznawaniu mowy i w tłumaczeniu tekstów. W przypadku cyberbezpieczeństwa coraz częściej wykorzystywany jest do wykrywania nazw wygenerowanych maszynowo. Hakerzy często używają jako front-end swojej infrastruktury świeżo zarejestrowane domeny, których nazwy składają się z losowych znaków. Zapewnia im to lepsze zaciemnienie infrastruktury i utrudnia inwestygacje po przeprowadzonym ataku. Parsując żądania DNS sieci neuronowe mogą sprawdzać czy dana nazwa została wygenerowana przez algorytm czy też nie. Analizując litery w ciągu znaków sprawdzane jest czy rzeczywista sekwencja liter zaczyna różnić się od przewidywanych i oczekiwanych kolejnych liter. Gdy tak się dzieje, to prawdopodobieństwo tego, że domena jest wygenerowana maszynowo wzrasta.
Dobre rady
Wszystkie powyższe algorytmy są narzędziami, które mogą być przydatne do wykrywania ataków, jeśli tylko stosowane są we właściwy sposób. Oprócz wspomnianych wcześniej wyzwań istnieją inne, istotne elementy, które są niezbędne do działania machine learning. Jednym z nich jest kontekst. Jest to wszystko to, co pomaga lepiej zrozumieć rolę obiektów uczestniczących w analizowanych danych. Są to informacje o urządzeniach, aplikacjach lub użytkownikach, takie jak lokalizacja, właściciel, funkcja urządzenia w środowisku itp. Drugą ważną rzeczą, o której bezpieczeństwo zapomina jest to, że systemy machine learning nie są niezależne i nieomylne. Nie wskazują bezpośrednio na rozwiązanie i często potrzebują potwierdzenia, że dana anomalia rzeczywiście jest atakiem i należy na nią zareagować.
Systemy bezpieczeństwa w organizacjach muszą być budowane z głową, tworzone z kilku elementów które współgrają ze sobą. Machine learning nie rozwiąże wszystkich problemów. Jest bardzo dobrą metodą wczesnego wykrywania lub przewidywania zagrożeń, jednak nie zastąpi kompletnego systemu obrony w organizacji.