Być może doczekaliśmy się przełomu w wykorzystaniu sztucznej inteligencji do analizy i wykrywania złośliwego oprogramowania. Sprawcą tego zamieszenia jest kolaboracja dwóch technologicznych gigantów – Microsoftu i Intela. Współpracują oni nad projektem badawczym, w którym wykorzystywane jest nowatorskie podejście do wykrywania i klasyfikacji malware. O klasycznym użyciu algorytmów uczenia maszynowego w cyberbezpieczeństwie pisaliśmy w artykule tutaj.
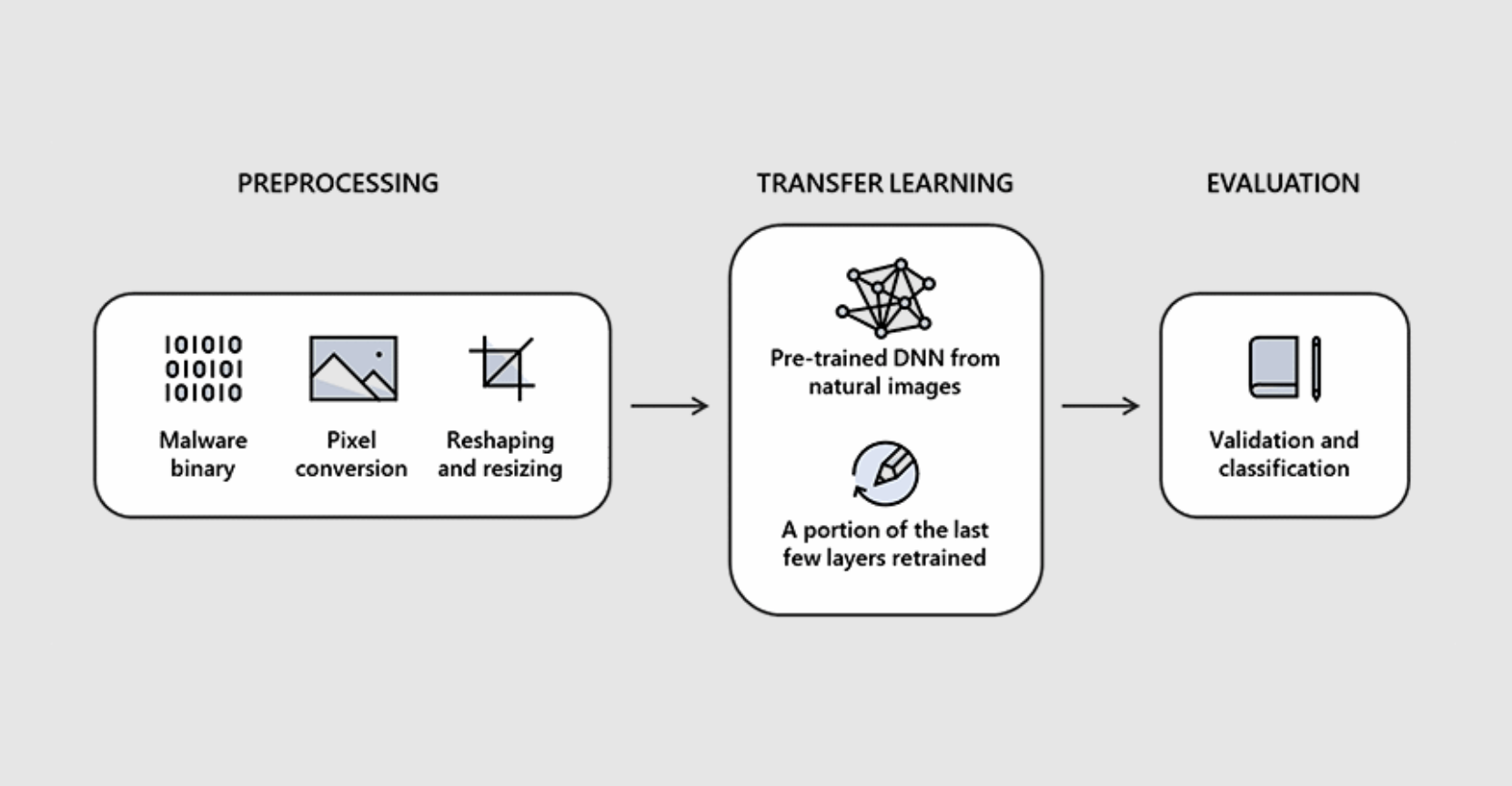
Projekt nosi nazwę STAMINA (ang. Static Malware-as-Image Network Analysis) i opiera się na przekształcaniu próbek złośliwego oprogramowania w obrazy w skali szarości, przepuszczaniu ich przez głęboką sieć neuronową i wyszukaniu wzorców strukturalnych charakterystycznych dla próbek złośliwego oprogramowania.
Od razu pojawia się pytanie – po co tak sobie utrudniać? Nic bardziej mylnego. Głębokie sieci neuronowe (ang. Deep Neural Networks, DNN) dają zdumiewające rezultaty, jeśli chodzi o wykrywanie charakterystycznych obiektów na obrazach. Wszystkie dzisiejsze nowoczesne technologie pozwalające na wyłuskanie obrazów z kamer, interesujących danych i przetworzenie ich, korzystają właśnie z implementacji DNN. Jeśli da się wykorzystać ten fakt w analizie próbek pod kątem złośliwego kodu, to zdecydowanie warto spróbować.
Jak działa STAMINA?
Zespół Intel-Microsoft opowiedział o całym procesie, jaki zachodzi, gdy analizowany jest plik pod kątem złośliwego kodu. Składa się on z kilku kroków.
- Pierwszy polega na pobraniu pliku wejściowego w postaci binarnej, zero-jedynkowej, i przekształceniu go w strumień surowych pikseli. Każdy bajt odpowiada jednemu pikselowi, a jego wartość od 0 do 255 to intensywność piksela w skali szarości.
- Następnie, jednowymiarowy strumień pikseli przekształcany jest na macierz pikseli, czyli obraz 2D, tak aby algorytmy analizy obrazu mogły go przeanalizować. Szerokość obrazu dobierana jest statycznie w zależności od rozmiaru strumienia. Wysokość wynika następnie z podzielenia strumienia danych przez wybraną wartość szerokości.
- Po złożeniu surowego strumienia pikseli w obraz 2D, naukowcy zmieniają wymiar uzyskanego zdjęcia na mniejszy. Ustalono bowiem, że odpowiednia operacja zmniejszenia wymiarów nie wpływa negatywnie na wynik klasyfikacji, a jest to konieczny krok, aby sieć neuronowa nie musiała pracować na obrazach składających się z miliardów pikseli, co spowalnia przetwarzanie.
- Zredukowane obrazy są potem wprowadzane do głębokiej sieci neuronowej (DNN), która przetwarza go i klasyfikuje jako plik czysty od malware bądź zainfekowany.
Microsoft podaje, że dostarczył 2,2 miliona zainfekowanych plików PE (Portable Executable), które służyły do nauczenia sieci i późniejszych testów. Naukowcy wykorzystali 60% próbek do wstępnego nauczenia algorytmu, 20% do sprawdzenia i weryfikacji oraz pozostałe 20% do faktycznych testów.
Ostatecznie udało się osiągnąć dokładność wynoszącą 99,07% w identyfikacji malware, przy współczynniku false positive wynoszącym 2,58%.
Co mówi Microsoft?
Microsoft otwarcie przyznaje, że zaczyna mocno inwestować w machine learning na wielu płaszczyznach, nie tylko w bezpieczeństwie. Sam projekt STAMINA uważa, za duży sukces i widzi jego zastosowanie jako moduł w aplikacji Defender wdrażany na serwery i stacje klienckie z systemami Windows. Przyznaje również, że nowatorskie podejście jest precyzyjne i szybkie oraz pozwala wykryć nieznany złośliwy kod w pliku wykonywalnym, ale ograniczeniem jest rozmiar takiego pliku. Przy większych plikach czas przetwarzania znacząco się wydłuża, a dokładność klasyfikacji maleje. „W przypadku aplikacji o większych rozmiarach STAMINA staje się mniej skuteczna z powodu ograniczeń w konwertowaniu miliardów pikseli na obrazy JPEG, a następnie redukcji rozmiaru”. Firma z Redmont dodaje, że korzysta już z wielu modeli uczenia maszynowego, które wspomagają wykrywanie malware po stronie klienta czy przetwarzają i analizują przechwyconą próbkę w chmurze. Głównie z tego powodu, Microsoft może odnieść sukces w implementacji nowej metody, opartej o głębokie uczenie. Posiadanie setek milionów wdrożeń Windows Defender na końcówkach w naturalnym środowisku, to ogromny zasób próbek i danych uczących dla algorytmów machine learning. Microsoft sam chwali się tym faktem i przyznaje, że dzięki temu osiągnęli tak dużą skuteczność.
Podsumowanie
Klasyczne metody wykrywania złośliwego oprogramowania polegają na pobieraniu i porównywaniu sygnatur binarnych lub „odcisków palców” złośliwego oprogramowania. Jednak ogromny wzrost liczby sygnatur powoduje, że dopasowywanie ich jest nieefektywne. Inne podejścia obejmują analizę statyczną i dynamiczną, które mają zalety i wady. Analiza statyczna dezasembluje kod, ale jej działanie może być nieskuteczne z powodu zaciemnienia kodu przez atakującego. Analiza dynamiczna, choć może rozpakować kod i dokładnie go przeanalizować, może być czasochłonna i również nieskuteczna. Wydaje się być nieuniknione, że rolę ochrony przed złośliwym oprogramowaniem w końcu w pełni przejmie sztuczna inteligencja i rozwijany deep learning. Dzięki zastosowanemu podejściu Microsoft razem z Intel, staje się to coraz bardziej możliwe.