






Mapa ataków na internetowych agentów AI
Badacze z Google DeepMind zidentyfikowali sześć typów ataków na agentów AI. Ataki te mogą być przeprowadzane za pomocą treści internetowych, tak by manipulować, wprowadzać w błąd i wykorzystywać autonomicznych agentów AI poruszających się po Internecie.
Autorzy artykułu wyjaśniają, że treści internetowe pozwalają atakującym tworzyć „pułapki na agentów AI”, za pomocą których wykorzystują możliwości agentów przeciwko nim samym, umożliwiając promowanie produktów, wykradanie danych lub masowe rozpowszechnianie informacji.
Zaprojektowane tak, by wprowadzać w błąd lub wykorzystywać wchodzących w interakcję agentów AI, elementy te mogą być osadzane w stronach internetowych lub innych zasobach cyfrowych i – jak twierdzą specjaliści – być „skalibrowane pod kątem zdolności agenta do wykonywania instrukcji, łączenia narzędzi i priorytetyzowania celów”.
Sześć rodzajów pułapek sklasyfikowanych przez badaczy Google DeepMind to: wstrzykiwanie treści, manipulacja semantyczna, stan poznawczy, kontrola zachowania, pułapki systemowe oraz pułapki z udziałem człowieka (human-in-the-loop).
Pułapki te wykorzystują różnicę między tym, co widzi człowiek, a tym, co analizuje maszyna, aby wstrzykiwać ukryte polecenia, manipulować danymi wejściowymi w celu zaburzenia rozumowania agenta, uszkadzać jego pamięć długoterminową, atakować zdolność wykonywania instrukcji poprzez jawne polecenia, wywoływać błędy na poziomie systemowym za pomocą spreparowanych danych wejściowych oraz wykorzystywać uprzedzenia poznawcze, aby nastawić agenta przeciwko nadzorującemu go człowiekowi.
1. Wstrzykiwanie treści
Jeśli chodzi o wstrzykiwanie treści, atakujący mogą używać instrukcji ukrytych w komentarzach HTML lub atrybutach metadanych, dynamicznie wstrzykiwać pułapki za pomocą JavaScriptu lub zapytań do baz danych, albo ukrywać je przy użyciu steganografii.
2. Manipulacja semantyczna
Pułapki manipulacji semantycznej opierają się na starannie dobranym języku, aby wywołać u agenta błędy poznawcze, omijać mechanizmy weryfikacji filtrujące szkodliwe lub niezgodne odpowiedzi albo „odbić” opis osobowości agenta z powrotem do niego, by zmienić jego zachowanie.
3. Uszkodzenie pamięci długotrwałej
Aby uszkodzić pamięć długoterminową agenta, pułapki związane ze stanem poznawczym zatruwają zewnętrzne źródła danych wykorzystywane przez niego, wstrzykują dane do wewnętrznych zasobów, takich jak trwałe logi, lub wykorzystują spreparowane interakcje środowiskowe do zmiany polityki jego działania.
4. Pułapki kontroli
Pułapki kontroli zachowania mają na celu wykorzystanie zdolności wykonywania instrukcji poprzez tzw. jailbreaki osadzone w zewnętrznych zasobach, zmuszenie agenta do ujawnienia uprzywilejowanych informacji poprzez niezaufane dane wejściowe lub nakłonienie go do tworzenia skompromitowanych podagentów działających z jego uprawnieniami, ale realizujących interesy atakującego.
5. Pułapki systemowe
Pułapki systemowe celują w zbiorowe zachowanie wielu agentów działających w tym samym środowisku, wykorzystując dynamikę między nimi, taką jak jednorodność, zależności sekwencyjne, synchronizacja zachowań i współpraca. Atakujący może także używać spreparowanych tożsamości do podważania założeń zaufania i procesów w systemach sieciowych.
6. Human in the loop
Jak wskazują badacze Google DeepMind, pułapki z udziałem człowieka (human-in-the-loop) mogą być użyte do przejęcia kontroli nad agentem i skierowania go przeciwko użytkownikowi. Na przykład niewidoczne wstrzyknięcia promptów mogą skłonić agenta do powtarzania poleceń ransomware jako instrukcji naprawczych.
Popularne

Uwaga! Trwa praktyczne wykorzystywanie krytycznej luki w systemach Fortinet!

Grupa ransomware ALP-001 twierdzi, że zaatakowała Polsat

DarkSword – cichy zabójca iPhone’ów. Nowy exploit, który przejmuje kontrolę nad urządzeniem w kilka sekund
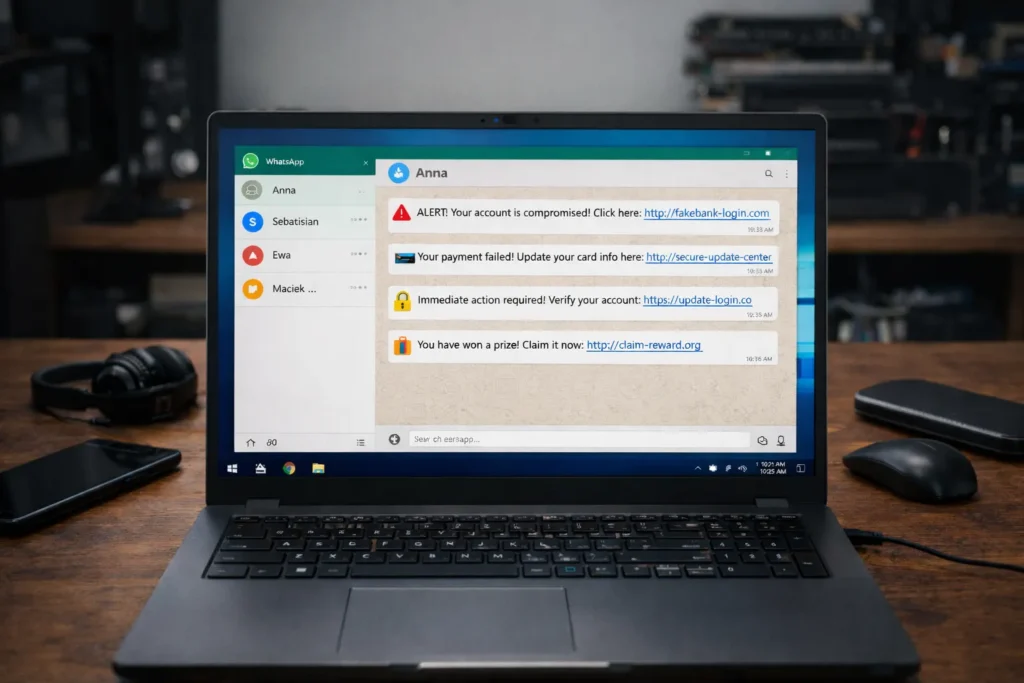
WhatsApp jako wektor ataku – Microsoft ostrzega przed nową kampanią malware ukrytą w wiadomościach

ClickFix na macOS, czyli jak użytkownicy sami instalują malware i jak Apple próbuje to powstrzymać
